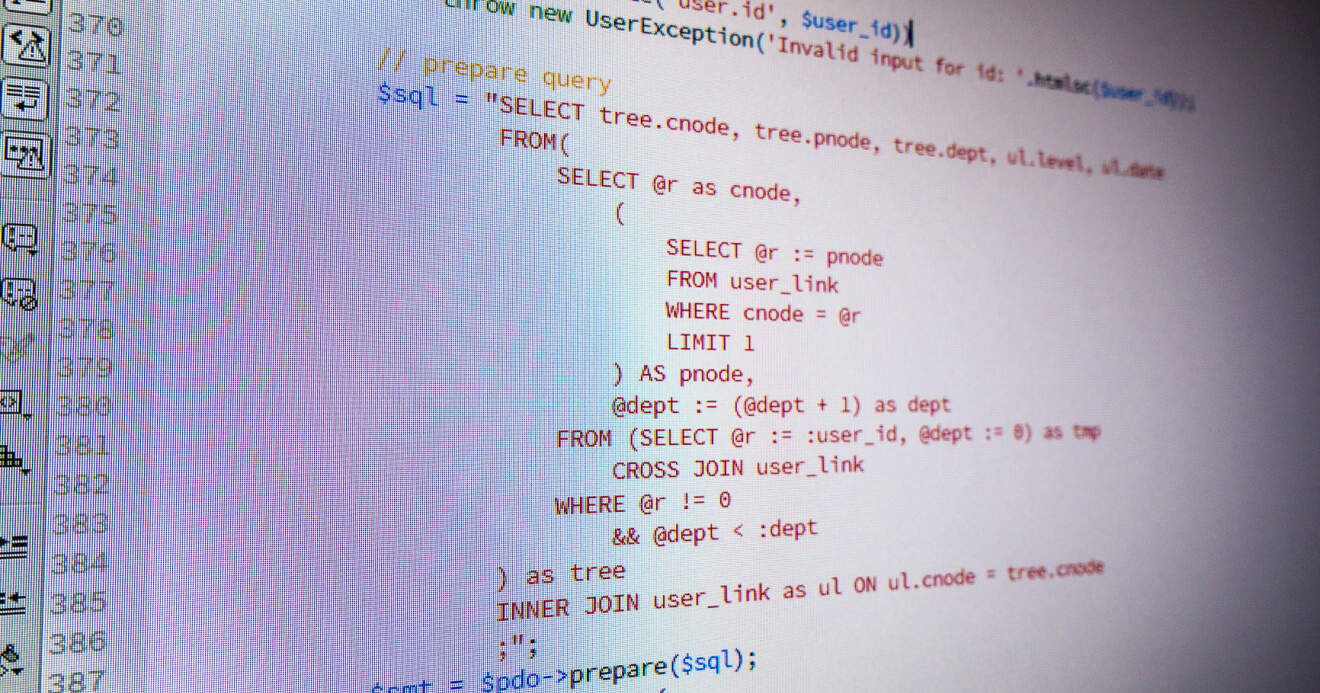
Kategorien oder Benutzerbeziehungen können oft hierarchisch aufgebaut sein. Hier sind die flachen MySQL Tabellen nicht besonders hilfreich. Mit dem nachfolgenden Query kann aber ein Ast aus dem Hierarchie-Baum an jeder beliebigen Stelle abgefragt werden.
Zuerst aber noch ein paar Worte zu solchen Tabellen im Allgemeinen. Das Design solcher Tabellen kann in mindestens 4 Arten erfolgen.
- Adjacency List
- Path Enumeration
- Netsted Sets
- Closure Tables
Die Adjacency List ist die wohl einfachste Art. Jeder Eintrag enthält eine Spalte mit dem Eltern-ID (Parent). Bei der Path Enumeration wird der gesamte Pfad in einer zusätzlichen Spalte mit Hilfe eines Trennzeichens gespeichert. Nested Sets basiert starkt auf dem Mengen- und Teilmengengedanken und Closure Tables speichern die Pfade (bzw. Beziehungen) in einer zweiten Tabelle.
Mehr über die Datenbankstrukturen von hierarchischen Tabellen findet ihr in der Präsentation Models for hierarchical data.
Wir werden uns jedoch nur um die erste Art kümmern, wobei die vierte Art die meines Erachtens sauberste wäre. Die Tabelle selbst sieht erstmal so aus:
CREATE TABLE `userlinks` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL,
`parent_id` int(10) unsigned NOT NULL,
`level` int(10) unsigned NOT NULL
PRIMARY KEY (`id`),
UNIQUE KEY `user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;Jede user_id hat also möglicherweise einen parent_id, die wiederum der user_id einer anderen Zeile entspricht. Hat ein Benutzer keinen Elternknoten so lautet die parent_id auf 0.
Um jetzt einen Ast ab einem bestimmten Eintrag bis zum obersten Elternknoten zu bekommen, können wir nun folgende Abfrage verwenden:
SELECT tree.user_id, tree.parent_id, tree.dept, ul.level
FROM(
SELECT @r as user_id,
(
SELECT @r := parent_id
FROM userlinks
WHERE user_id = @r
LIMIT 1
) AS parent_id,
@dept := (@dept + 1) as dept
FROM (SELECT @r := 97, @dept := 0) as tmp
CROSS JOIN userlinks
WHERE @r != 0
&& @dept < 5
) as tree
INNER JOIN userlinks as ul ON ul.cnode = tree.cnodeErklärung: Beginnen wir innen. Wir erzeugen eine neue Tabelle tmp, die aus @r und @dept besteht und verbinden diese mit CROSS JOIN mit unserer Verlinkungstabelle. Aus dieser Tabelle holen wir uns nun das erste @r (welches natürlich unserem Ausgangspunkt entsprechen muss, hier: 97) sowie die Eltern-ID parent_id dieses Eintrag mithilfe eines Subquery. Gleichzeitig mit der Abfrage wird auch unsere @r Variable neu gesetzt. Die Eltern-ID wird nun zur User-ID. Als dritten Wert holen wir uns noch die Tiefe dept und erhöhen die zugehörige Variable vorher noch um 1. Dies geht solange gut, bis eine Zeile erreicht wird, deren parent_id den Wert 0 hat. Hier springt unsere WHERE Bedingung ein und stoppt den Vorgang.
In diesem Beispiel hört die Suche ebenfalls einer Tiefe von 5 auf. Möchte man alle Eltern bis zum obersten abfragen, muss man einfach die Zeile && @dept < 5 löschen.
Das äußerste SELECT ist nur noch ein Wrapper um unter anderem das Level zu bekommen.
Angesichts dieser Lösung stellt sich die Frage, warum die meisten Antworten auf StackExchange & Co. dermaßen komplex sind. Einziger Nachteil dieser Abfrage ist, dass stest die gesamte Tabelle mit der erzeugten tmp Tabelle gekreuzt wird, was bei sehr vielen Datensätzen zu einem Performance-Abfall führen kann. Diesen Nachteil hätte aber auch Struktur 4 bzw. der unnormalisierte Variante in Form von Struktur 2. Für mich ist diese Lösung jedenfalls praktikabel und einsatzfähig!
{kind=link}